Improving Speech Intelligibility in Reverberant Environments
Backgrounds
In public spaces (e.g. multiple-purpose halls, train stations and
airports) where public address systems transmit speech signals via loudspeakers,
we receive the speech signals with reverberation. It is sometimes difficult to
understand speech in such reverberant environments, especially for people with
hearing impairments, elderly people, and non-native listeners. Reverberation
masks speech segments that follows (i.e. overlap-masking (Nabelek et al., 1989)), and this degrades speech intelligibility. It is pointed out
that when a previous segment has strong energy (e.g. a vowel), the following
segments (e.g. a consonant) can be significantly smeared in reverberation (Arai
et al., 2001, 2002). When we compare
an original and a reverberant speech signals in Figure 1, we can see the
envelope of the reverberant speech signal is smeared by
reverberation.
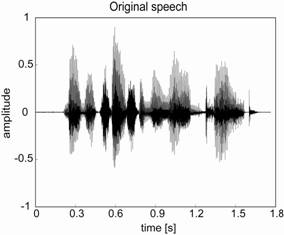
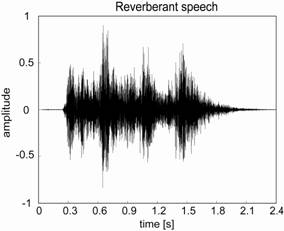
Figure 1. Original (left) and reverberant (right) speech signals
Approaches
The goal of this study is to achieve “barrier-free listening
environments” in reverberant environments, which means providing intelligible
speech signals not only for young people but for elderly people, people with
hearing impairments and non-native listeners in public spaces. We have studied
this from two approaches: the public address system side and the talker side
(See Figure 2).
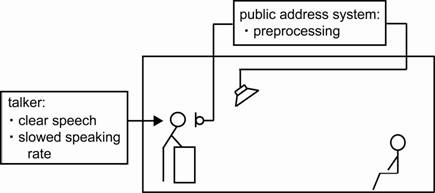
Figure 2. Two approaches to provide “barrier-free listening
environments”
As an approach of the public address system side, we have proposed
“pre-processing” (i.e. processing a speech signal before we send it from
loudspeakers). Pre-processing might be beneficial in public spaces where
different kind of people listen to speech signals because we don’t need to
attach special listening devices to reduce the effect of reverberation.
We have proposed two pre-processing approaches: modulation filtering
(e.g. Kusumoto et al., 1999, 2005)
and steady-state suppression (Arai et
al., 2001, 2002; Hodoshima et
al., 2006). Modulation filtering alters the temporal dynamics of speech
(i.e. temporal modulation). This approach enhances particular low-frequency
components of the temporal modulation (i.e. below 16Hz) which are important for
speech perception (Houtgast and Steeneken, 1985).
Steady-state suppression effectively suppresses steady-state portions
of speech (e.g. vowel nuclei) that have high energy in order to reduce
overlap-masking (See Figure 3). The information in steady-state portions of a
speech signal is relatively unimportant compared to transitions (Furui, 1986),
therefore this approach can minimize the effect of overlap-masking without
degrading speech intelligibility as much as possible.
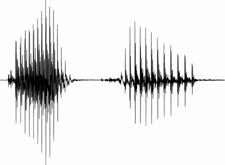
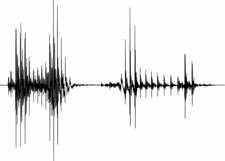
Figure 3. Original (left) and steady-state suppressed (right) signals
of the word /aka/
As an approach of the talker side, we have studied speech signals
which are robust to reverberation. Speech intelligibility changes by talkers as
well as by speaking style (e.g. clear, conversational) or speaking rate (slow,
normal, fast) within an individual talker. This approach seeks characteristics
of intelligible speech signals as well as the effect of clear speech and slowed
speaking rate in reverberation (e.g. Hodoshima et al., 2007).
Major findings
Different public spaces have different room conditions, and the
optimum approach would be different in different public spaces. So, we have
studied from the public address system side and the talker side under various
listening conditions.
Below are our major findings:
1) The public address system side
- Modulation filtering improved consonant identification for young
people with normal hearing in reverberation (Kusumoto et al., 2005).
- People with severe hearing loss preferred processed speech signals
by modulation filtering as easier to hear compared to unprocessed speech signals
in reverberation (Kusumoto et al.,
1999, 2000).
- Steady-state suppression significantly improved consonant
identification (e.g. Arai et al.,
2007; Hodoshima et al., 2005,
2006, 2008a; Miyauchi et al., 2005;
Nakata et al.,
2006)
- both in simulated reverberant environments and in a lecture hall
(reverberation times of 0.7-1.3 s),
- both for young people with normal hearing and for elderly
people,
- in both normal and slowed speaking rate.
2) The talker side (Hodoshima et al., 2007,
2008b)
- "Clear" speech had higher speech intelligibility than
"conversational" speech by grouping young listeners' hearing impression of
speech signals uttered by talkers who were told as if they spoke in
reverberation.
Future works
We believe that our research contributes to realizing “barrier-free
listening environment” for elderly people, people with hearing-impairment and
non-native listeners as well as designing an algorithm for hearing aids
(Kobayashi et al.,
2008).
Speech demos (to be updated soon)
References
S. Furui, “On the role of spectral transition for speech perception.”
J. Acoust. Soc. Am., 80(4), 1016-1025, 1986.
T. Houtgast and H. J. M. Steeneken, “A review of MTF concept in room
acoustics and its use for estimating speech intelligibility in auditoria.” J.
Acoust. Soc. Am., 77(3), 1069-1077, 1985.
A. K. Nabelek, T. R. Letowski and F. M. Tucker, “Reverberant overlap- and
self-masking in consonant identification.” J. Acoust. Soc. Am., 86(4),
1259-1265, 1989.
T. Arai, K. Kinoshita,
T. Arai, K. Kinoshita,
T. Arai, K. Yasu and N. Hodoshima, “Effective speech processing for
various impaired listeners,'' Proc. International Congress on Acoustics, II,
1389-1392, 2004 (Invited Paper).
T. Arai, “Padding zero into steady-state portions of speech as a
preprocess for improving intelligibility in reverberant environments,'' Acoust.
Sci. Tech., 25(5), 459-461, 2005.
T. Arai and
T. Arai, “Preprocessing speech against reverberation,'' J. Acoust.
Soc. Am., 120(5), 3323, 2006 (Invited Paper).
T. Arai, Y. Nakata,
T. Arai, Y. Murakami, N. Hayashi,
N. Hayashi, T. Arai,
N. Hayashi,
N. Hodoshima, T. Arai and A. Kusumoto, “Enhancing temporal dynamics
of speech to improve intelligibility in reverberant environments,'' Proc. Forum
Acusticum, 2002.
N. Hodoshima, T. Inoue, T. Arai and A. Kusumoto, “Suppressing
steady-state portions of speech for improving intelligibility in various
reverberant environments,'' Proc. China-Japan Joint Conference on Acoustics,
199-202, 2002.
N. Hodoshima, T. Arai, T. Inoue, K. Kinoshita and A. Kusumoto,
“Improving speech intelligibility by steady-state suppression as pre-processing
in small to medium sized halls,'' Proc. Eurospeech, 1365-1368,
2003.
N. Hodoshima, T. Arai, T. Inoue, K. Kinoshita and A. Kusumoto,
“Improving intelligibility of speech by steady-state suppression as
pre-processing in small to medium sized halls,'' International Workshop on
Speech Dynamics by Ear, Eye, Mouth and Machine, Technical Report of IEICE Japan,
SP2003-53, 61-66, 2003.
N. Hodoshima, T. Inoue, T. Arai, A. Kusumoto and K. Kinoshita,
“Suppressing steady-state portions of speech for improving intelligibility in
various reverberant environments,'' Acoust. Sci. Tech., 25(1), 58-60,
2004.
N. Hodoshima, T. Goto, N. Ohata, T. Inoue and T. Arai, “The effect of
pre-processing for improving speech intelligibility in the Sophia University
lecture hall,'' Proc. International Congress on Acoustics, III, 2389-2392,
2004.
N. Hodoshima, T. Arai, A. Kusumoto and K. Kinoshita, “Improving
syllable identification by a preprocessing method reducing overlap-masking in
reverberant environments,'' J. Acoust. Soc. Am., 119(6), 4055-4064,
2006.
N. Hodoshima and T. Arai, “Investigating an optimum suppression rate
of steady-state portions of speech that improves intelligibility the most as a
pre-processing approach in reverberant environments,'' J. Acoust. Soc. Am.,
118(3), 1930, 2005.
N. Hodoshima, D. Behne and T. Arai, “Steady-state suppression in
reverberation: A comparison of native and nonnative speech perception,'' Proc.
Interspeech, 873-876, 2006.
N. Hodoshima, T. Arai and P. Svensson, “The effect of a preprocessing
approach improving speech intelligibility in reverberation considering a
public-address system and room acoustics,'' J. Acoust. Soc. Am., 120(5), 3359,
2006.
N. Hodoshima, D. Behne and T. Arai, “The effect of the steady-state
suppression on consonant identification by native and non-native listeners in
reverberant environments,'' International Workshop on Frontiers in Speech and
Hearing Research, Technical Report of IEICE Japan, SP2005-165, 15-20,
2006.
N. Hodoshima and T. Arai, "Effect of talker variability on speech
perception by elderly people in reverberation" in the Handbook of Auditory
signal processing in hearing-impaired listeners. International Symposium on
Auditory and Audiological Research, edited by T. Dau, J. M. Buchholz, J. M.
Harte and T. U. Christiansen (Centertryk A/S, Holbaek), 383-387,
2007.
N. Hodoshima, Y. Miyauchi, K. Yasu and T. Arai, "Steady-state
suppression for improving syllable identification in reverberant environments: A
case study in an elderly person," Acoust. Sci. Tech., 28(1), 53-55,
2007.
N. Hodoshima, P. Svensson and T. Arai, “Preprocessing effects on
speech intelligibility in reverberation using mixed natural and
electroacoustical sounds,'' Proc. Japan-China Joint Conference of Acoustics,
2007.
N. Hodoshima, T. Arai and K. Kurisu, “Effects of training, style, and
rate of speaking on speech perception of young people in reverberation,”
Acoustics 08 Paris, 2393-2397, 2008.
N. Hodoshima, W. Yoshida and T. Arai, “Improving consonant
identification in noise and reverberation by steady-state suppression as a
preprocessing approach,” Proc. Interspeech, 1793-1796,
2008.
T. Goto, T. Inoue, N. Ohata, N. Hodoshima and T. Arai, “The effect of
pre-processing for improving speech intelligibility in the Sophia University
lecture hall,'' Proc. Autumn Meet. Acoust. Soc. Jpn., 1, 613-614, 2003 (in
Japanese, Poster Award).
T. Kitamura, K. Kinoshita, T. Arai, A. Kusumoto and Y. Murahara,
“Designing modulation filters for improving speech intelligibility in
reverberant environments,'' Proc. ICSLP, 3, 586-589, 2000.
K. Kobayashi, Y. Hatta, K. Yasu, S. Minamihata, N. Hodoshima, T. Arai
and M. Shindo, “Improving speech intelligibility for elderly listeners by
steady-state suppression,'' International Workshop on Frontiers in Speech and
Hearing Research, Technical Report of IEICE Japan, SP2005-168, 31-36,
2006.
K. Kobayashi, K. Yasu,
A. Kusumoto, T. Arai, T. Kitamura, M. Takahashi and Y. Murahara,
“Speech processing on the room acoustics for the hearing-impaired,'' Proc.
Autumn Meet. Acoust. Soc. Jpn., 1, 389-390, 1999 (in
Japanese).
A. Kusumoto, T. Arai, T. Kitamura, M. Takahashi and Y. Murahara,
“Modulation enhancement of speech as a preprocessing for reverberant chambers
with the hearing-impaired,'' Proc. IEEE ICASSP, 2, 853-856,
2000.
A. Kusumoto, T. Arai, K. Kinoshita, N. Hodoshima and
Y. Miyauchi, N. Hodoshima, K. Yasu, N. Hayashi, T. Arai and M.
Shindo, “A preprocessing technique for improving speech intelligibility in
reverberant environments: The effect of steady-state suppression on elderly
people,'' Proc. Interspeech, 2769-2772, 2005.
Y. Miyauchi and T. Arai, “Energy suppression of steady-state portions
of vowels while maintaining the energy of consonants better improves speech
intelligibility for elderly listeners in reverberation,'' J. Acoust. Soc. Am.,
120(5), 3346-3347, 2006.
Y. Nakata, Y. Murakami, N. Hodoshima and T. Arai, “Slowed speech
spreading into reverberant environments; steady-state suppression improves
speech intelligibility,'' J. Acoust. Soc. Am., 120(5), 3360,
2006.
Y. Nakata, Y. Murakami, N. Hodoshima, N. Hayashi, Y. Miyauchi, T.
Arai and K. Kurisu, “The effects of speech-rate slowing for improving speech
intelligibility in reverberant environments,'' International Workshop on
Frontiers in Speech and Hearing Research, Technical Report of IEICE Japan,
SP2005-166, 21-24, 2006.
K. Takahashi, K. Yasu,